伪指令可以变更查询计划。可以使用特定伪指令来强制优化器选择特定类型的查询计划,例如一个使用散列连接和查询中显示表的顺序的查询计划。
以下示例显示了伪指令如何变更查询计划。
假定您有以下查询:
SELECT * FROM emp,job,dept
WHERE emp.location = 10
AND emp.jobno = job.jobno
AND emp.deptno = dept.deptno
AND dept.location = "DENVER";
假设存在以下索引:
ix1:emp(empno、jobno、deptno、location) ix2:job (jobno) ix3:dept (location)
使用 SET EXPLAIN ON 运行查询可显示优化器使用的查询路径。
QUERY:
------
SELECT * FROM emp,job,dept
WHERE emp.location = "DENVER"
AND emp.jobno = job.jobno
AND emp.deptno = dept.deptno
AND dept.location = "DENVER"
Estimated Cost: 5
Estimated # of Rows Returned: 1
1) gbasedbt.emp: INDEX PATH
Filters: gbasedbt.emp.location = 'DENVER'
(1) Index Keys: empno jobno deptno location (Key-Only)
2) gbasedbt.dept: INDEX PATH
Filters: gbasedbt.dept.deptno = gbasedbt.emp.deptno
(1) Index Keys: location
Lower Index Filter: gbasedbt.dept.location = 'DENVER'
NESTED LOOP JOIN
3) gbasedbt.job: INDEX PATH
(1) Index Keys: jobno (Key-Only)
Lower Index Filter: gbasedbt.job.jobno = gbasedbt.emp.jobno
NESTED LOOP JOIN
图 1 中的图表显示了该查询的一个可能的查询计划。
查询计划有三个层次的信息:(1) 嵌套循环连接;(2) 针对一个表的索引扫描和一个嵌套循环连接;(3) 针对其他两个表的索引扫描。
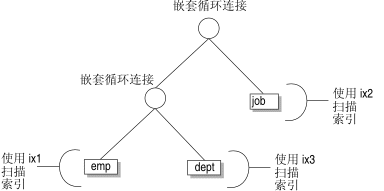
图: 不使用伪指令的可能查询计划
您可能会担心,使用嵌套循环连接可能不是执行该查询的最快方法。您还会认为连接顺序不是最优的。您可以强制优化器选择散列连接并对查询计划中的表进行排序(根据它们在查询中的次序),因此,优化器使用图 2 显示的查询计划。
此查询计划有三个层次的信息:(1) 散列连接,(2) 索引扫描和散列连接,以及 (3) 针对其他两个表的索引扫描。
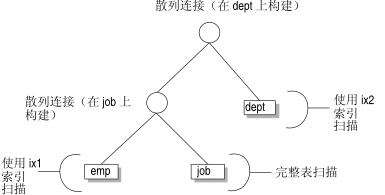
图: 使用伪指令的可能查询计划
要强制优化器选择使用散列连接的查询计划和查询中显示的表的顺序,请使用以下部分 SET EXPLAIN 输出显示的伪指令:
QUERY:
------
SELECT {+ORDERED,
INDEX(emp ix1),
FULL(job),
USE_HASH(job /BUILD),
USE_HASH(dept /BUILD),
INDEX(dept ix3)}
* FROM emp,job,dept
WHERE emp.location = 1
AND emp.jobno = job.jobno
AND emp.deptno = dept.deptno
AND dept.location = "DENVER"
DIRECTIVES FOLLOWED:
ORDERED
INDEX ( emp ix1 )
FULL ( job )
USE_HASH ( job/BUILD )
USE_HASH ( dept/BUILD )
INDEX ( dept ix3 )
DIRECTIVES NOT FOLLOWED:
Estimated Cost: 7
Estimated # of Rows Returned: 1
1) gbasedbt.emp: INDEX PATH
Filters: gbasedbt.emp.location = 'DENVER'
(1) Index Keys: empno jobno deptno location (Key-Only)
2) gbasedbt.job: SEQUENTIAL SCAN
DYNAMIC HASH JOIN
Dynamic Hash Filters: gbasedbt.emp.jobno = gbasedbt.job.jobno
3) gbasedbt.dept: INDEX PATH
(1) Index Keys: location
Lower Index Filter: gbasedbt.dept.location = 'DENVER'
DYNAMIC HASH JOIN
Dynamic Hash Filters: gbasedbt.emp.deptno = gbasedbt.dept.deptno